


.png?width=610&name=J1_ModernCybersecurityBook_Promo%201200x628%20v2@2x%20(1).png)

Liz Fong-Jones has 11 years of experience in SRE and previously worked at Google. Now she’s the principle dev advocate at Honeycomb.
In this session, she discussed infrastructure practices at Honeycomb. First, Honeycomb provides observability for development teams. And they have to ship new features quickly as well as provide a lot of reliability for their customers.
The fundamentals for infrastructure are the same as for building a reliable service. They want to empower teams to explore the data that those teams need to explore their systems.
Friday Deployments and Feature Follow-Up
Yes, it’s true. Honeycomb does deploy on Fridays. But there’s no “push and run,” where developers push code to production at 5 p.m. and then head home for the weekend. They stick around and observe what the new feature is doing in production.
Here’s a graph showing that Honeycomb’s developers push to production several times a day:
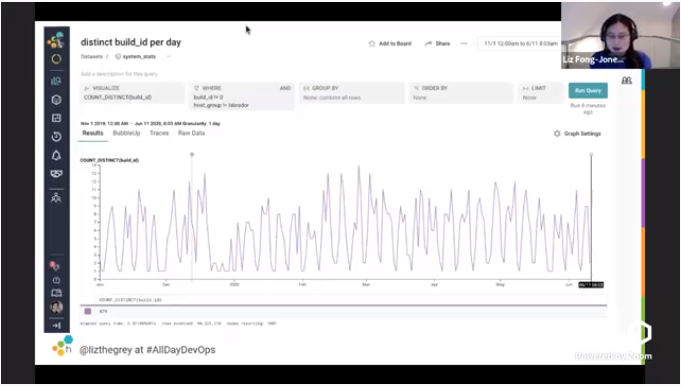
How do they make it happen? They need the right tooling, but nothing too complex. They also carefully choose what to build in-house and what to outsource. And they need cultural processes, too.
Additionally, they needed to continuously evaluate tech debt, deciding how to prioritize that among all their work.
Honeycomb embraces risk, but its staff also mitigates it in order to respond when things don’t go according to plan.
After Deployment: Product Team
Let’s look at two different journeys. One for the developers on the product team, and one for infrastructure folks.
First, what’s it like for engineers on the product team? Well, they start by instrumenting as they code, similar to how application developers have tests right at the beginning instead of tacking them on at the end.
Next, they verify that changes are behaving as expected in a sandbox environment. And those changes are all behind feature flags, so they can always turn one off. They also keep their main branch in a deployable state.
Additionally, any time the build times in their pipeline get too lengthy, they spend time making it better.
They also use both human and automated review to make sure the right features are getting into production. To top it off, they’ve created more opportunities for mitigation by adding in auto-updates, rollback, and pins.
As Fong-Jones mentioned earlier, they don’t push and run. In fact, they also have a dog food environment where they monitor their own applications using Honeycomb and verify that things are working correctly before leaving for the day.
In short, that’s how 12 engineers deploy 12 hours a day.
In DORA metrics, lead time defines the time between writing a feature and that feature hitting production. Right now, Honeycomb is looking at three-hour lead times!
When we focus on lead time, deployment frequency goes up. Likewise, change failure rate and deploy time goes down.
Now let’s look at the next journey.
After Deployment: Infrastructure Engineers
What does this look like from an infrastructure side? Infrastructure engineers empower the product. So, Kubernetes isn’t the goal—it’s not a résumé booster. Instead, the mission is to achieve reliability and simplicity. Is this technology the right thing for the company?
Where do you start? If infrastructure is messy, automate the painful parts, fix the duct tape, and keep the environment clean and reproducible.
Interestingly, at Honeycomb, raw VMs are simpler than containers. Infrastructure engineers cold boot from Chef and then use cron to repeatedly practice this. They also centralize state and locking, along with diff and release using Terraform Cloud, similarly to what application developers do with application code.
So, Honeycomb’s engineers can write their code, put it in GitHub, and see what it will do to the infrastructure. And then they’re more confident in rollbacks in case of problems.
This also lets Honeycomb’s engineers deploy incrementally—even for infrastructure. Feature flags aren’t just for application code.
Honeycomb’s engineers also use ephemeral fleets and autoscaling to deal with spikes and loads. They also can put up temporary workspaces that can deal with problems, such as quarantining excessive or bad traffic to protect the rest of the customers.
So, What Isn’t Working at Honeycomb?
The team size has doubled, and if processes don’t change in turn, there will be scaling issues. Commits have gone up as well. Now, two, three, or five teams can hit the main branch all at once.
Plus, customer traffic is increasing. So, Honeycomb has new bottlenecks.
For example, they have SLOs where 99.99% of the time, they store telemetry. And 99.9% of the time, the dashboards load in one second. And 99% of the time, queries come back in 10 seconds. They have to protect those SLOs.
The previous deploy system deployed to all three services at once. That doesn’t work as well with the increased load. Therefore, Honeycomb’s SLOs are in danger. Additionally, releases aren’t granular enough, and manual rollbacks have been too slow.
Honeycomb’s needs are no longer simple. For example, previously Fong-Jones said that Kubernetes wasn’t necessary. But maybe they now have a need for a tool like Spinnaker.
So, now there’s a need to step back and reevaluate the state.
What’s Next?
More growth is still ahead. Honeycomb wants to launch new services easily. As more devs join the company, they all can’t be working on three mini-monoliths simultaneously. And they need to consider how to save money. These are all important considerations for operational expenses.
But the most important thing for Honeycomb is to keep their people healthy and happy, letting them sleep easily at night.
This session was summarized by Sylvia Fronczak. Sylvia is a software developer that has worked in various industries with various software methodologies. She’s currently focused on design practices that the whole team can own, understand, and evolve over time.

